Introduction
Créé le 2010-11-23 et mis à jour le 2010-11-24 par André Gillibert
 Bonjour ! Voici le premier article de l'Angry GNU User. Une critique des logiciels buggés et bloatés et plus spécifiquement de GNU. Mes critiques ne s'appliquent pas à Linux, un noyau qui a échappé à la maladie affectant les logiciels GNU. En effet, le noyau Linux ne fait pas partie du projet GNU proprement dit, et se trouve être plutôt bien pensé. Bien que ce soit un projet titanesque, Linux a d'excellentes performances et une taille binaire plutôt raisonnable par rapport à l'ampleur du projet, et un code suffisamment compréhensible pour être facilement modifié, alors que le programme GNU le plus simple fera facilement des centaines de kilo-octets et sera d'une lenteur injustifiée.
Bonjour ! Voici le premier article de l'Angry GNU User. Une critique des logiciels buggés et bloatés et plus spécifiquement de GNU. Mes critiques ne s'appliquent pas à Linux, un noyau qui a échappé à la maladie affectant les logiciels GNU. En effet, le noyau Linux ne fait pas partie du projet GNU proprement dit, et se trouve être plutôt bien pensé. Bien que ce soit un projet titanesque, Linux a d'excellentes performances et une taille binaire plutôt raisonnable par rapport à l'ampleur du projet, et un code suffisamment compréhensible pour être facilement modifié, alors que le programme GNU le plus simple fera facilement des centaines de kilo-octets et sera d'une lenteur injustifiée.
Alors que le nombre des lignes du noyau Linux servent ses performances, son parallélisme, lui permettant de battre la concurrence sur des systèmes de centaines de processeurs surchargés en calculs et entrées-sorties, les outils GNU semblent multiplier les lignes de code pour permettre la compatibilité avec les bouliers, mais en pratique ne font qu'augmenter la probabilité d'une erreur de compilation ou d'un dysfonctionnement, tout spécialement sur système qui ne soit pas à 100% GNU, ou qui soit âgé de quelques années.
Je ne crois pas que l'on puisse aimer la manière GNU de travailler dès lors qu'on en étudie le code source. Même les Makefiles, censés aider à la compréhension de la compilation, ne font que la rendre obscure et incompréhensible, par la complexité extrême d'autotools. Au final, ces outils ne permettent pas de maîtriser les binaires générés, surtout dans un contexte de compilation croisée, et on en arrive à produire des binaires ne fonctionnant pas sur les systèmes antérieurs à celui utilisé pour la compilation. Certains outils comme libtool empirent encore le tableau par leurs bugs et leur obscur fonctionnement.
La manie des outils GNU de constamment étendre les standards, de supprimer ou ajouter fréquemment ces extensions, de dépendre de celles-ci dans d'autres outils, avec des relations parfois incestueuses comme celle entre GLIBC et GCC, rendent le système GNU à la fois monolithique, ne laissant prèsque aucune place pour le mélange GNU/non-GNU, mais aussi très volatil, puisque chaque outil se transforme perpétuellement, rendant la compilation même de ce monolithe difficile, puisque seules certaines combinaisons de versions précises d'outils sont à même d'aboutir à un système fonctionnel. Quant au fonctionnement des binaires, il ne vaut mieux même pas y penser, puisque rares sont les projets portant la moindre attention à la compatibilité binaire, même si la GLIBC fait exception à la règle. Au final, il est nécessaire de bien connaître le système GNU et les langages de programmation si on veut le compiler, puisqu'on en arrivera forcément à éditer le code source manuellement. D'ailleurs la création des distributions GNU/Linux est née de ce besoin d'avoir un système fonctionnel.
À mon avis, les distributions Linux sont des systèmes centralisés, et leur utilisation aveugle, c'est à dire sans installation de paquets autres que ceux fournis par la distribution, sans compilation manuelle de projets tierces, est contraire aux principes de liberté de choix du logiciel libre et mène à la formation de communautés dans des jardins fermés, pires que celui du système Microsoft Windows qui a une économie décentralisée de logiciels tierces parties. Heureusement, si on utilise une distribution Linux seulement comme base pour un système entièrement personnalisé, alors là, on peut conserver sa liberté. Pour cela, il suffit d'être motivé et de savoir compiler les programmes, même si GNU rend la tâche difficile.
Le système GNU permet la modification des logiciels à usage personnel, mais par la licence GPL, rend difficile le partage des modifications personnelles, puisqu'elles sont susceptibles de mélanger le code de plusieurs licences incompatibles et demande de plus une infrastructure de distribution assez rigide, rendant difficile de partager des binaires améliorés manuellement, sans processus automatisé.
True story
 Un seul octet : C3. La simplicité même. Quel rêve ! 0xC3 est le code binaire du programme true.com le plus simple pour MS-DOS. Une simple instruction RET branche à l'adresse CS:0000 qui ensuite saute à la routine de sortie équivalente et renvoie zéro; compatibilité avec CP/M oblige.
Un seul octet : C3. La simplicité même. Quel rêve ! 0xC3 est le code binaire du programme true.com le plus simple pour MS-DOS. Une simple instruction RET branche à l'adresse CS:0000 qui ensuite saute à la routine de sortie équivalente et renvoie zéro; compatibilité avec CP/M oblige.
/bin/true est le programme le plus simple qui soit. Il se contente de ne rien faire, puis renvoyer toujours zéro. Sur toutes les plateformes, il s'agit d'un programme théoriquement trivial. Pour MS-DOS il peut ne faire qu'un seul octet. Pour Linux/ELF/i386 on peut s'en tirer à 83 octets, et un programme naïf écrit en assembleur fait 123 octets après que l'on en ait supprimé les "section headers" avec un programme automatique. 232 octets pour un programme naïf écrit en C, statiquement lié à la dietlibc. N'importe quel imbécile sachant tout juste compiler un "hello world!" peut générer un /bin/true naïf dynamiquement lié à la GLIBC de 6 ou 7 kilo-octets sans même le passer par strip(1), et pourtant le /bin/true de coreutils 7.4 sur i386, optimisé avec -Os fait 22972 octets dynamiquement lié à la GLIBC. Que contiennent ces kilo-octets inutiles ?
La réponse est courte. À l'éloigner de la norme POSIX et à le ralentir.
Nous allons étudier du plus haut niveau au plus bas niveau le /bin/true de coreutils.
Conformité
/bin/true n'est pas conforme à la norme POSIX 2003 par défaut. En effet, celle-ci recommande que /bin/true ignore toutes les variables d'environnement et les paramètres sur la ligne de commande tandisque le /bin/true de coreutils reconnaît spécialement --help et --version à moins que la variable d'environnement POSIXLY_CORRECT soit correctement assignée (pour les anciennes versions de coreutils, les dernières ayant été modifiées pour ne plus en tenir compte car maintenant POSIX 2008 autorise ce comportement). De plus, comme tous les exécutables dynamiques, il traite spécialement nombre de variables d'environnement telles que LD_PRELOAD ou LD_SHOW_AUXV qui ne sont pourtant pas réservées à l'implémentation par la norme POSIX, ce qui détruit la compatibilité avec POSIX 2008. Le /bin/true naïf statiquement lié à la GLIBC ou la dietlibc est pourtant conforme à la norme POSIX 2003 et POSIX 2008 !
Portabilité des binaires
 À cause de son lien dynamique à la GLIBC, des problèmes de compatibilité binaire apparaissent. Par exemple compilé sur une machine dotée de la GLIBC >= 2.3, il peut requérir des symboles nécessitant au moins la GLIBC 2.3. Compilé avec Fedora 6, il va aussi nécessiter un ld-linux.so supportant les sections .gnu.hash, même si c'est un problème lié à Fedora, il est inutilement introduit par l'usage abusif de librairies dynamiques. Enfin, sur x86_64, il va obliger l'utilisateur à disposer de la version 32 bits de la GLIBC.
À cause de son lien dynamique à la GLIBC, des problèmes de compatibilité binaire apparaissent. Par exemple compilé sur une machine dotée de la GLIBC >= 2.3, il peut requérir des symboles nécessitant au moins la GLIBC 2.3. Compilé avec Fedora 6, il va aussi nécessiter un ld-linux.so supportant les sections .gnu.hash, même si c'est un problème lié à Fedora, il est inutilement introduit par l'usage abusif de librairies dynamiques. Enfin, sur x86_64, il va obliger l'utilisateur à disposer de la version 32 bits de la GLIBC.
Encore à cause du lien dynamique, un système avec une GLIBC compilée pour un noyau 2.6 va faire échouer /bin/true sur un noyau 2.4 avec un message indiquant que le noyau est trop ancien. Une GLIBC moderne va vouloir au moins un noyau 2.6.9. Un /bin/true ELF naïf écrit en assembleur ou en C+dietlibc va fonctionner avec un noyau 1.2 ou supérieur!
Performances
Sur un Pentium 4 Northwood 2.67Ghz, 512 MiO de RAM, noyau Linux 2.6.30.4, GLIBC 2.9, avec un programme trivial effectuant 5000 fork/exec de true, les résultats de timings sont:
| Programme | naïf statique dietlibc | naïf statique GLIBC | naïf dynamique GLIBC | coreutils 7.4 dynamique GLIBC |
| Durée de 5000 forkexecs | 250ms +/- 5 ms | 520ms +/- 5ms | 1980ms +/- 20ms | 2150ms +/- 30ms |
| Taille | 232 octets | 474860 octets | 5560 octets | 22972 octets |
En conclusion, la lenteur est essentiellement due au lien dynamique, un peu due au bloat monstrueux de la GLIBC, et enfin seulement 10% sont est lié au bloat de coreutils. Encore un argument contre les liens dynamiques.
Compilation du code
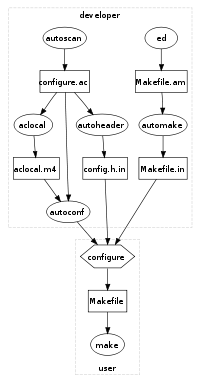 L'examination des horribles Makefiles de coreutils renseigne peu sur les dépendances de /bin/true. Le meilleur moyen de retrouver les fichiers .c nécessaires est par essais et échecs de compilation sur une ligne de commande. On en arrive à la ligne suivante:
L'examination des horribles Makefiles de coreutils renseigne peu sur les dépendances de /bin/true. Le meilleur moyen de retrouver les fichiers .c nécessaires est par essais et échecs de compilation sur une ligne de commande. On en arrive à la ligne suivante:
gcc -Os -I .. -I . -I../lib true.c ../lib/closeout.c ../lib/close-stream.c ../lib/basename.c ../lib/progname.c ../lib/hard-locale.c ../lib/version-etc.c ../lib/quotearg.c ../lib/exitfail.c ../lib/xalloc-die.c ../lib/xstrndup.c ../lib/vfprintf.c ../lib/version-etc-fsf.c ../lib/xmalloc.c ../lib/vasnprintf.c ../lib/fseterr.c -lm ../lib/printf-parse.c ../lib/printf-args.c ../lib/isnanl.c version.c
Cette ligne de 398 octets est plus grande, en octets, que la réunion du code source et du code binaire d'un /bin/true naïf écrit en C et statiquement lié à la diet libc !
Pourquoi toutes ces dépendances ? Réponse courte : Surtout pour fermer stdout ! Pourquoi ? Parce que si jamais un programme affichait des données sur stdout et omettait de faire un fflush(3) ou fclose(3) et d'en vérifier la valeur de retour, il se pourrait que tous les fwrite(3) aient réussis alors que les dernières données n'aient pas pu être correctement écrites et que le programme renvoie pourtant une valeur de succès. Pour pallier à ce problème inexistant de /bin/true, une commande atexit(close_stdout) enregistre une fonction qui fera ce travail automatiquement, d'où la dépendance à closeout.c.
closeout.c et close-stream.c contiennent un algorithme déterminant si oui ou non le programme a écrit des données sur stdout et si oui ou non, il faut échouer. Super, comme ça, il y a un peu de chance que dans des conditions extrêmes /bin/true échoue !
basename.c est utilisé pour déterminer le nom du fichier exécutable de /bin/true comme la commande basename(1), pour pouvoir afficher un joli message pour --help. Il alloue de la mémoire avec des fonction xmalloc ou xstrndup ! Yipee le truc qui échoue quand on s'y attend le moins. Évidemment, plutôt que de renoncer à afficher un joli nom de programme lorsque l'allocation échoue, /bin/true préfère faire un abort(3) bien bourrin. Vive le sixième commandement du programmeur C !
progname.c est un autre moyen de calculer le nom du programme, cette fois utilisé en cas d'erreur de close_stdout. Il n'alloue pas de mémoire. Ouf.
error.c dont dépendent closeout.c et xalloc-die.c appelle fprintf sur stderr de manière assez élaborée. C'est bourré de GNU-ismes invoquant des fonctions non documentées telles que __libc_ptf_call ainsi que de la compilation conditionnelle à souhait, histoire de rendre la compilation difficile sur des plateformes ne disposant pas de la GLIBC. Tant qu'on y est, error() fait un fflush(stdout) alors qu'un fclose(stdout) a été effectué avant l'appel à error(). La première de ces opérations est déjà suspecte, mais la seconde a certainement un comportement indéfini. POSIX contient:
After the call to fclose(), any use of stream causes undefined behaviour.
Bon, error_tail() contient aussi plein de code de conversion de message en unicode avec des fonctions qui peuvent échouer (alloca, malloc, mbstowcs)... Il faut dire que le standard C99 oblige a ne pas mélanger les sorties mbs et wcs et cette fonction est appelée dans un contexte qui ne connaît pas le mode d'orientation de stderr. Voilà ce qui arrive quand on écrit du code générique.
version-etc.c sert à l'affichage de la version (--version), et contient plus de logique qu'on l'eût cru. Par exemple, en fonctions du nombre d'auteurs passés en paramètre, un gros switch avec 11 cas différents, détermine le formattage approprié. Si le nombre d'auteurs est supérieur ou égal à 11, les derniers auteurs ne sont même pas listés. Tant qu'on y est, ce code effectue un abort() s'il n'y a aucun auteur, heureusement, /bin/true passe un nom d'auteur en paramètre.
hard-locale.c détermine si la locale correspond à la locale C/POSIX ou si elle est plus complexe. Code un peu subtil si la libc n'est pas la GLIBC. Ce code est utilisé par system.h dans la fonction inline emit_bug_reporting_address (oui,le C99 est requis). Ainsi --help affiche un message "Report true translation bugs to <http://translationproject.org/team/>
" si et seulement si la locale n'est ni C ni POSIX.
quotearg.c est utilisé par closeout.c en cas d'échec... Il sert à échapper les caractères spéciaux contenus dans le nom du programme /bin/true au cas où il contiendrait un caractère deux-points. C'est du bon gros code générique d'échappement faisant environ 3.5 kilo-octets de code binaire. Évidemment, il alloue de la mémoire et fait un abort() si l'allocation échoue, histoire d'échouer même dans l'échec.
*printf*.c est une réimplémentation de printf parce que GNU est tellement buggé qu'il ne fait même pas confiance au code de printf de la GLIBC. C'est bien la dernière fonction que l'on voudrait réimplémenter. Commme ça /bin/true est dynamiquement lié à GLIBC, avec tous les problèmes de portabilité des binaires impliqués, mais ne bénéficie même pas des bugfixes des nouvelles versions de GLIBC concenant printf. De plus, /bin/true y gagne une grosse quantité de kilo-octets. En plus, pour avoir le pire des deux, /bin/true utilise aussi le vrai printf. /bin/true --version fait appel à la librairie interne de coreutils, et ainsi utilise le faux printf, tandisque /bin/true --help utilise le printf de la GLIBC, heureusement, puisqu'autrement, lorsque /bin/true --help se trouverait appelé avec un nom de plus de 2000 octets, il échouerait (voir vfprintf.c), ce qui peut arriver s'il est enfoncé très profondément dans une hiérarchie de répertoires et appelé par son chemin d'accès absolu.
fseterr.c utilisé par *printf*.c, il assigne le bit d'erreur d'un stream FILE* à 1. Pour cela, il accède directement à la structure non documentée d'un FILE, avec de la compilation conditionnelle en fonction de la plateforme, assurant de belles surprises lors des updates de la GLIBC, parce que même si la GLIBC tente d'être binairement compatible d'une version à l'autre, cela ne concerne que la partie documentée de la librairie. On peut s'attendre à ce que /bin/true échoue sa compilation dans un futur prochain. Okay, les gars de GLIBC pouvant coopérer avec ceux de coreutils ce ne sera peut-être pas aussi catastrophique que ça. Par contre, sur les autres plateformes (*BSD, Cygwin, AIX, HP-UX, IRIX, OSF/1, Solaris, MinGW, QNX, FreeMiNT, etc.) je ne vois pas pourquoi ils se préoccuperaient de coreutils. Le "portable fallback" n'a pas l'air vraiment portable, la norme POSIX ne spécifiant pas le comportement de fputc(3) après la fermeture du descripteur de fichier sous-jacent. De toute façon, le "portable fallback" n'est pas utilisé sur les plateformes précédemment citées.
isnan.c que vasnprintf utilise, contient moults suppositions non portables sur la représentation des flottants. Heureusement ce code n'est, à priori, jamais appelé par /bin/true.
/bin/true de coreutils: Conclusion
/bin/true est buggé et bloaté. Le bug du fflush(3) après fclose(3) est même susceptible d'être exploité dans une attaque ! La question est pourquoi ?
- Par négligence. Les programmeurs ne mesurant pas du tout l'ampleur des dépendances indirectement induites par le simple atexit(close_stdout), pourtant inutile sinon dangereux puisqu'il vaut mieux renvoyer zéro même si /bin/true --version échoue l'affichage complet du nom de version.
- Par volonté de donner un aspect et un comportement GNU à tous les programmes. Ainsi, la gestion de --version et --help témoigne de cet esprit. Heureusement c'est maintenant autorisé par POSIX 2008.
- Par volonté de contourner les bugs des autres, tel que la réimplémentation de printf, ayant pour effet d'induire nombre de hacks violant les standards. Le contournement de bug, c'est très bien du moment que ça n'implique pas des bugs plus grâves !
- Par la dépendance de librairies programmées de manière générique, telles que la mini-librairies interne de coreutils ou la GLIBC. Ces librairies tentant de fonctionner dans toutes les conditions possibles, en pratique, ne sont qu'un tas très fragile de hacks divers, générateurs d'erreurs à la compilation ou à l'exécution lorsque des conditions imprévues apparaissent.
- Par connaissance trop intime du système, comme en témoigne l'appel ridicule à des fonctions non documentées de la GLIBC comme __libc_ptf_call qui n'a de sens que dans un système multithread.
Le bloat n'est pas exclusivement retrouvé dans /bin/true. C'est une constante des logiciels GNU. /bin/true n'en est que la plus simple expression. La GLIBC est nettement pire que coreutils, puisqu'un /bin/true naïf statique fait 474 kilo-octets avec la GLIBC 2.9, mais c'est une autre histoire.
Bonus: Le /bin/true de MINIXv3
GNU n'a pas le monopole de la médiocrité, Minix fait fort avec le /bin/true le plus buggé qu'il m'ait jamais été donné de voir. Le code vous en dira plus:
#!/bin/sh
#
# cd 1.3 - equivalents for normally builtin commands. Author: Kees J. Bot
case $0 in
*/*) command="`expr "$0" : '.*/\(.*\)'`"
;;
*) command="$0"
esac
"$command" "$@"
Okay, un script shell, mais pourquoi pas un code vide ou à la rigueur un simple exit 0 ? Pour ceux qui n'auraient pas compris, le shell commence par déterminer le nom de fichier d'invocation, en omettant le préfixe de répertoire, puis appelle la commande par son propre nom avec ses propres paramètres. En court, c'est équivalent à :
#!/bin/sh
true
 Une fork bomb ! Le programme le plus simple au monde est une fork bomb sous Minix ! Un programme récursif s'invoquant indéfiniment ! Enfin, pas tout à fait. Si "true" est une commande interne du shell, le script va invoquer la commande interne et immédiatement renvoyer une valeur de succès. C'est le cas pour le /bin/sh de Minix, mais, /bin/true est spécifiquement conçu pour les cas où on dispose d'un shell pour lequel ce n'est pas une commande interne. Si on remplace /bin/sh par un tel shell, /bin/true devient bel et bien une fork bomb. Le même résultat est obtenu si on renomme /bin/true en /bin/nom_improbable. De toute façon, utiliser $0 est une mauvaise idée. Le comportement d'un programme ne devrait pas dépendre de son nom d'invocation sauf exception.
Une fork bomb ! Le programme le plus simple au monde est une fork bomb sous Minix ! Un programme récursif s'invoquant indéfiniment ! Enfin, pas tout à fait. Si "true" est une commande interne du shell, le script va invoquer la commande interne et immédiatement renvoyer une valeur de succès. C'est le cas pour le /bin/sh de Minix, mais, /bin/true est spécifiquement conçu pour les cas où on dispose d'un shell pour lequel ce n'est pas une commande interne. Si on remplace /bin/sh par un tel shell, /bin/true devient bel et bien une fork bomb. Le même résultat est obtenu si on renomme /bin/true en /bin/nom_improbable. De toute façon, utiliser $0 est une mauvaise idée. Le comportement d'un programme ne devrait pas dépendre de son nom d'invocation sauf exception.
Pouquoi ce code délirant ? Parce que le même script est utilisé pour toutes les commandes internes pour lesquelles un script a été créé dans /bin, telles que /bin/false, /bin/test ou /bin/echo. Ce n'est pas une excuse. Les fichiers ne sont même pas des liens symboliques. Le code est recopié ! Encore pire, des commandes internes qui n'ont aucun sens en programme externe sont néammoins présents dans /bin, comme wait, cd ou read.
Les performances ne sont pas si minables car expr est une commande interne du shell. Au final sur un Athlon64 3000+ et MINIXv3.1.2a 5000 forkexec nécessitent 2 secondes.
Conclusion
/bin/true doit être trop simple pour que l'on en fasse une implémentation naïve. À force de vouloir faire mieux, tout le monde arrive à des /bin/true buggés et lents.